Script Location from ORACLE-BASE
http://oracle-base.com/dba/scripts.php
.
--- Blogs ---
http://pjacksondba.blogspot.com/
http://tkyte.blogspot.com/
http://blog.tanelpoder.com/
http://jonathanlewis.wordpress.com/
http://carymillsap.blogspot.com/
http://karenmorton.blogspot.com/
Database Server Upgrade/Downgrade Compatibility Matrix (Doc ID 551141.1)
Patching & Maintenance Advisor: Database (DB) Oracle Database 11.2.0.x (Doc ID 331.1)
Oracle Recommended Patches -- Oracle Database (Doc ID 756671.1)
Introduction to Oracle Recommended Patches (Doc ID 756388.1)
Oracle Recommended Patches (PSU) for Enterprise Manager Base Platform (All Releases) (Doc ID 822485.1)
-- For Upgrade and Install
Oracle® Grid Infrastructure Installation Guide 12c Release 1 (12.1) for Microsoft Windows x64 (64-Bit) E49041-03
-- Oracle Database Online Documentation 12c Release 1 (12.1)
https://docs.oracle.com/database/121/nav/portal_11.htm
Oracle® Grid Infrastructure Installation Guide 11g Release 2 (11.2) for IBM AIX on POWER Systems (64-Bit) E48294-01
Oracle® Grid Infrastructure Installation Guide 12c Release 1 (12.1) for IBM AIX on POWER Systems (64-Bit)
-- For Upgrade and Install
http://mirrors.iyunwei.com/oracle/docs/12.1-E16655-01/install.121/e38943.pdf
--
Oracle Database 12c R1 RAC on IBM AIX
http://www-03.ibm.com/support/techdocs/atsmastr.nsf/5cb5ed706d254a8186256c71006d2e0a/781e2275188c706886257c98006b1c6e/$FILE/IBM%20AIX%20Oracle%2012cR1-tips_SHANMUGAM%2026%20Feb%202014.pdf
--
http://docs.oracle.com/database/121/nav/portal_booklist.htm





When it comes to measuring a storage system's overall performance, Input/Output Operations Per Second (IOPS) is still the most common metric in use. There are a number of factors that go into calculating the IOPS capability of an individual storage system.
In this article, I provide introductory information that goes into calculations that will help you figure out what your system can do. Specifically, I explain how individual storage components affect overall IOPS capability. I do not go into seriously convoluted mathematical formulas, but I do provide you with practical guidance and some formulas that might help you in your planning. Here are three notes to keep in mind when reading the article:
Sample drive:
However, rather than working through a formula for your individual disks, there are a number of resources available that outline average observed IOPS values for a variety of different kinds of disks. For ease of calculation, use these values unless you think your own disks will vary greatly for some reason.
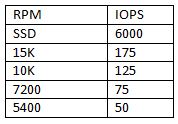
Below I list some of the values I've seen and used in my own environment for rough planning purposes. As you can see, the values for each kind of drive don't radically change from source to source.

Note : SSDS IOPS = 6000
Sources:
Let's explore what happens when you start looking at other RAID levels.
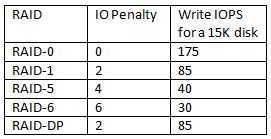
For example, for each random write request, RAID 5 requires many disk operations, which has a significant impact on raw IOPS calculations. For general purposes, accept that RAID 5 writes require 4 IOPS per write operation. RAID 6's higher protection double fault tolerance is even worse in this regard, resulting in an "IO penalty" of 6 operations; in other words, plan on 6 IOPS for each random write operation. For read operations under RAID 5 and RAID 6, an IOPS is an IOPS; there is no negative performance or IOPS impact with read operations. Also, be aware that RAID 1 imposes a 2 to 1 IO penalty.
The chart below summarizes the read and write RAID penalties for the most common RAID levels.

Parity-based RAID systems also introduce other additional processing that result from the need to calculate parity information. The more parity protection you add to a system, the more processing overhead you incur. As you might expect, the overall imposed penalty is very dependent on the balance between read and write workloads.
A good starting point formula is below. This formula does not use the array IOPS value; it uses a workload IOPS value that you would derive on your own or by using some kind of calculation tool, such as the Exchange Server calculator.
(Total Workload IOPS * Percentage of workload that is read operations) + (Total Workload IOPS * Percentage of workload that is read operations * RAID IO Penalty)
Source: http://www.yellow-bricks.com/2009/12/23/iops/
As an example, let's assume the following:
This could be an unpleasant surprise for some organizations, as it indicates that the number of disks might be more important than the size (i.e., you'd need twelve 7,200 RPM, seven 10K RPM, or five 15K RPM disks to support this IOPS need).
If you want more proof that the iSCSI/Fibre Channel choice doesn't necessarily directly impact your IOPS calculations, read this article on NetApp's site.
The transport choice is an important one, but it's not the primary choice that many would make it out to be. For larger organizations that have significant transport needs (i.e., between the servers and the storage), Fibre Channel is a good choice, but this choice does not drive the IOPS wagon.
In this article, I provide introductory information that goes into calculations that will help you figure out what your system can do. Specifically, I explain how individual storage components affect overall IOPS capability. I do not go into seriously convoluted mathematical formulas, but I do provide you with practical guidance and some formulas that might help you in your planning. Here are three notes to keep in mind when reading the article:
- Published IOPS calculations aren't the end-all be-all of storage characteristics. Vendors often measure IOPS under only the best conditions, so it's up to you to verify the information and make sure the solution meets the needs of your environment.
- IOPS calculations vary wildly based on the kind of workload being handled. In general, there are three performance categories related to IOPS: random performance, sequential performance, and a combination of the two, which is measured when you assess random and sequential performance at the same time.
- The information presented here is intended to be very general and focuses primarily on random workloads.
IOPS calculations
Every disk in your storage system has a maximum theoretical IOPS value that is based on a formula. Disk performance -- and IOPS -- is based on three key factors:- Rotational speed (aka spindle speed). Measured in revolutions per minute (RPM), most disks you'll consider for enterprise storage rotate at speeds of 7,200, 10,000 or 15,000 RPM with the latter two being the most common. A higher rotational speed is associated with a higher performing disk. This value is not used directly in calculations, but it is highly important. The other three values depend heavily on the rotational speed, so I've included it for completeness.
- Average latency. The time it takes for the sector of the disk being accessed to rotate into position under a read/write head.
- Average seek time. The time (in ms) it takes for the hard drive's read/write head to position itself over the track being read or written. There are both read and write seek times; take the average of the two values.
Sample drive:
- Model: Western Digital VelociRaptor 2.5" SATA hard drive
- Rotational speed: 10,000 RPM
- Average latency: 3 ms (0.003 seconds)
- Average seek time: 4.2 (r)/4.7 (w) = 4.45 ms (0.0045 seconds)
- Calculated IOPS for this disk: 1/(0.003 + 0.0045) = about 133 IOPS
However, rather than working through a formula for your individual disks, there are a number of resources available that outline average observed IOPS values for a variety of different kinds of disks. For ease of calculation, use these values unless you think your own disks will vary greatly for some reason.
Below I list some of the values I've seen and used in my own environment for rough planning purposes. As you can see, the values for each kind of drive don't radically change from source to source.
Note : SSDS IOPS = 6000
Sources:
- http://blog.aarondelp.com/2009/10/its-now-all-about-iops.html
- http://www.yellow-bricks.com/2009/12/23/iops/
- http://www.tomshardware.com/forum/251893-32-raid-raid
Multidisk arrays
Enterprises don't install a single disk at a time, so the above calculations are pretty meaningless unless they can be translated to multidisk sets. Fortunately, it's easy to translate raw IOPS values from single disk to multiple disk implementations; it's a simple multiplication operation. For example, if you have ten 15K RPM disks, each with 175 IOPS capability, your disk system has 1,750 IOPS worth of performance capacity. But this is only if you opted for a RAID-0 or just a bunch of disks (JBOD) implementation. In the real world, RAID 0 is rarely used because the loss of a single disk in the array would result in the loss of all data in the array.Let's explore what happens when you start looking at other RAID levels.
The IOPS RAID penalty
Perhaps the most important IOPS calculation component to understand lies in the realm of the write penalty associated with a number of RAID configurations. With the exception of RAID 0, which is simply an array of disks strung together to create a larger storage pool, RAID configurations rely on the fact that write operations actually result in multiple writes to the array. This characteristic is why different RAID configurations are suitable for different tasks.For example, for each random write request, RAID 5 requires many disk operations, which has a significant impact on raw IOPS calculations. For general purposes, accept that RAID 5 writes require 4 IOPS per write operation. RAID 6's higher protection double fault tolerance is even worse in this regard, resulting in an "IO penalty" of 6 operations; in other words, plan on 6 IOPS for each random write operation. For read operations under RAID 5 and RAID 6, an IOPS is an IOPS; there is no negative performance or IOPS impact with read operations. Also, be aware that RAID 1 imposes a 2 to 1 IO penalty.
The chart below summarizes the read and write RAID penalties for the most common RAID levels.
Parity-based RAID systems also introduce other additional processing that result from the need to calculate parity information. The more parity protection you add to a system, the more processing overhead you incur. As you might expect, the overall imposed penalty is very dependent on the balance between read and write workloads.
A good starting point formula is below. This formula does not use the array IOPS value; it uses a workload IOPS value that you would derive on your own or by using some kind of calculation tool, such as the Exchange Server calculator.
(Total Workload IOPS * Percentage of workload that is read operations) + (Total Workload IOPS * Percentage of workload that is read operations * RAID IO Penalty)
Source: http://www.yellow-bricks.com/2009/12/23/iops/
As an example, let's assume the following:
- Total IOPS need: 250 IOPS
- Read workload: 50%
- Write workload: 50%
- RAID level: 6 (IO penalty of 6)
This could be an unpleasant surprise for some organizations, as it indicates that the number of disks might be more important than the size (i.e., you'd need twelve 7,200 RPM, seven 10K RPM, or five 15K RPM disks to support this IOPS need).
The transport choice
It's also important to understand what is not included in the raw numbers: the transport choice -- iSCSI or Fibre Channel. While the transport choice is an important consideration for many organizations, it doesn't directly impact the IOPS calculations. (None of the formulas consider the transport being used.)If you want more proof that the iSCSI/Fibre Channel choice doesn't necessarily directly impact your IOPS calculations, read this article on NetApp's site.
The transport choice is an important one, but it's not the primary choice that many would make it out to be. For larger organizations that have significant transport needs (i.e., between the servers and the storage), Fibre Channel is a good choice, but this choice does not drive the IOPS wagon.